Architektur des Data Hub Berlin
Die Architektur des Data Hub Berlin bildet das technische Rückgrat der Plattform. Sie basiert auf CIVITAS/CORE, einer offenen, modularen Architektur, die moderne Cloud-Technologien mit einem klaren Fokus auf Nachnutzbarkeit, Sicherheit und Skalierbarkeit verbindet.
Technische Leitprinzipien
Die Architektur des Data Hub Berlin folgt vier grundlegenden Prinzipien, die sicherstellen, dass die Plattform langfristig erweiterbar, interoperabel und zukunftsfähig bleibt.
Im Mittelpunkt steht der Einsatz von Cloud-nativen Technologien. Durch den containerbasierten Aufbau und die Orchestrierung über Kubernetes kann der Data Hub flexibel betrieben werden, vollständig in der Cloud. Die Plattform lässt sich bei Bedarf automatisch skalieren, also vergrößern, und reagiert so dynamisch auf wachsende Anforderungen.
Die Architektur ist explizit mit Blick auf Kompatibilität und Skalierbarkeit entwickelt worden. Offene Schnittstellen und standardisierte Kommunikationsprotokolle ermöglichen die einfache Integration neuer Datenquellen, Anwendungen oder Fachverfahren. Damit kann der Data Hub mit den Bedürfnissen seiner Nutzenden mitwachsen.
Ein weiterer Grundpfeiler ist die konsequente Nutzung von Open Source-Komponenten. Diese Entscheidung schafft Transparenz und Unabhängigkeit von einzelnen Anbietern. Gleichzeitig fördert sie die Nachnutzbarkeit und den Wissenstransfer mit anderen Städten und öffentlichen Einrichtungen.
Schließlich folgt der Data Hub einem modularen Baukastenprinzip. Jede Funktion, vom Dateneingang über die Verarbeitung bis zur Visualisierung, ist als eigenständiges Modul umgesetzt. Dadurch kann die Plattform gezielt erweitert, angepasst oder um neue Funktionen ergänzt werden, ohne dass der Betrieb beeinträchtigt wird.
Gemeinsam ermöglichen diese Prinzipien einen robusten, sicheren und flexiblen Betrieb der Plattform und bilden damit das Fundament einer nachhaltige Dateninfrastruktur in der Berliner Verwaltung.
Architekturaufbau
Die technische Basis des Data Hub Berlin orientiert sich am Microservice-Prinzip. Jede Aufgabe, wie etwa die Aufnahme von Sensordaten oder das Bereitstellen von Geodiensten, wird von einem eigenen, spezialisierten Software Diensten übernommen.
Diese Dienste laufen in Kubernetes-Clustern, die für Ausfallsicherheit, Lastverteilung und automatische Skalierung sorgen. So kann der Data Hub auch bei hohem Datenaufkommen gezielt Ressourcen erweitern, ohne dass andere Komponenten betroffen sind.
Das zentrale API-Gateway (APISIX) bündelt alle Schnittstellen der Plattform. Es regelt Authentifizierung, Routing und Monitoring und stellt sicher, dass Datenflüsse zwischen internen Diensten und externen Anwendungen kontrolliert und sicher sind.
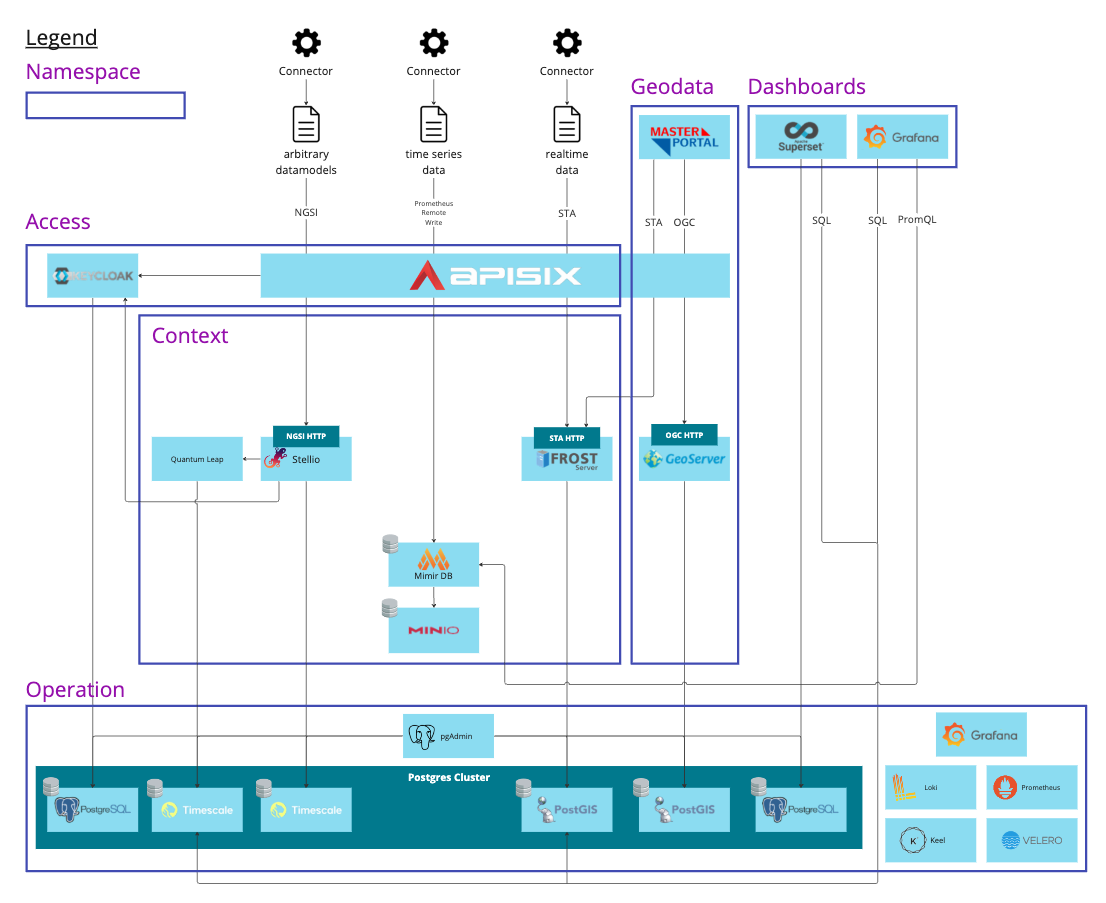
Schematische Darstellung der Komponenten und ihrer Verbindungen in der CIVITAS/CORE-Architektur (Quelle: Civitas Connect)
Zentrale Komponenten im Überblick
Die CIVITAS/CORE-Architektur gliedert sich in mehrere Schichten, die gemeinsam den Weg der Daten vom Eingang bis zur Nutzung abbilden.
1. Datenerfassung (Ingestion)
In dieser Schicht werden Daten aus Fachverfahren, Geodiensten, Sensoren oder externen Quellen aufgenommen. Sie können als Datei-Uploads, API-Zugriffe oder kontinuierliche Datenströme in den Data Hub gelangen. Bereits bei der Aufnahme erfolgt eine Validierung, damit Daten in konsistenter Struktur weiterverarbeitet werden können.
2. Kontext- und Sensordatenmanagement (Stellio & FROST Server)
Der Stellio Context Broker dient als System zur Verwaltung von Kontextinformationen, das heißt Daten, die zeitlich, räumlich oder semantisch miteinander verknüpft sind. Er ermöglicht es, komplexe Beziehungen zwischen Objekten, wie etwa Standorte, Zustände oder Ereignisse, abzubilden. So lassen sich beispielsweise Messstationen mit ihren aktuellen Werten, Positionen und zugehörigen Sensoren logisch miteinander verbinden.
Der FROST Server ergänzt dieses System durch die Erfassung und Verwaltung kontinuierlicher Sensordatenströme. FROST empfängt Daten in Echtzeit, speichert sie als Zeitreihen und stellt sie über standardisierte Endpunkte wieder bereit.
4. Datenverwaltung (Storage Layer)
Die Speicherung der Daten erfolgt je nach Typ in unterschiedlichen Systemen: strukturierte Verwaltungsdaten werden in relationalen Datenbanken wie PostgreSQL / PostGIS abgelegt. Große unstrukturierte Datenmengen, wie etwa Bildateien, oder Dateien die aus lokalen Dateien in den Data Hub überführt werden müssen, werden im Objektspeicher MinIO abgelegt.
5. API- und Zugriffsschicht (APISIX)
Das API-Gateway (APISIX) bildet die Schnittstelle zwischen Backend und Nutzungsschicht. Es kontrolliert Zugriffsrechte, überwacht die Nutzung und leitet Anfragen an die jeweils zuständigen Dienste weiter. Es gewährleistet die Sicherheit und Performance von externen Zugriffen auf die Plattform.
6. Nutzung und Visualisierung
Über browserbasierte Dienste wie Masterportal, Grafana oder Appsmith können Nutzende mit den Daten arbeiten, sie visualisieren oder über Formulare erfassen. In dieser Ebene können Data Hub Nutzende selbst Daten auswerten und gemeinsam digitale Anwendungen entwickeln, ohne in die weitere technische Infrastruktur eingreifen zu müssen.
Für Verwaltungsmitarbeitende heißt das: Der Einstieg in die Arbeit mit dem Data Hub erfolgt in der Nutzungsebene, also dort, wo Daten sichtbar, analysierbar und anwendbar werden, ohne sich mit der darunterliegenden Infrastruktur beschäftigen zu müssen. Die technischen Komponenten wie Kubernetes, APISIX oder die Datenmanagement-Schicht laufen im Hintergrund und müssen von Verwaltungsmitarbeitenden nicht direkt bedient werden.
Offene Schnittstellen & Standards
Die Architektur des Data Hub Berlin setzt konsequent auf offene, standardisierte Schnittstellen. Diese sorgen dafür, dass Daten zwischen den einzelnen Komponenten austauschbar bleiben und auch auch von zukünftigen Erweiterungen nutzbar bleiben.
Unterstützte Schnittstellen und Protokolle:
- OpenAPI Specification (REST) – Beschreibung der Microservice-Endpunkte
- OGC SensorThings API (STA) – Standard für IoT- und Sensordaten (FROST Server)
- NGSI-LD – Kontextdatenmodell und API (Stellio Context Broker)
- OGC Web Services (WMS, WFS, WCS) – Bereitstellung und Abfrage von Geodaten (GeoServer)
- DCAT-AP – Standard für Metadaten und offene Verwaltungsdaten
- JSON-LD / Linked Data – semantische Beschreibung von Datenobjekten
- MQTT / WebSocket – Protokolle für Echtzeitdatenübertragung
- HTTPS / REST – sichere Kommunikation zwischen allen Diensten
Weiterführende Informationen
Diese Seite bietet einen Überblick über die technische Architektur des Data Hub Berlin. Für vertiefende Informationen zur technischen Implementierung stehen folgende Quellen zur Verfügung:
-
CIVITAS/CORE Dokumentation für weitere technische Details zu Architektur:
CIVITAS/CORE Architektur Dokumentation
CIVITAS/CORE Repository -
Offizielle Website des Projekts Civitas Connect, dem Verein hinter CIVITAS/CORE. Hintergrund, Zielsetzung und Open-Source-Ansatz der Plattform:
Civitasconnect.digital