Datenbasiertes Monitoring in Bibliotheken
Was verraten Bibliotheksdaten über das Kulturangebot in der Stadt? Womit erreichen Bibliotheken besonders viele Menschen? Und wie können Räume und Gelder effizient genutzt werden? Eine Dashboard-Lösung soll sichtbar machen, wie sich Nutzung, Bestand und Zukäufe in der Stadtteilbibliothek Pankow entwickeln. Es wird damit zu einem zentralen Werkzeug, um künftig Bedarfserfassung und Makulatur datenbasiert zu vereinfachen.

Wie datenbasiert arbeiten Bibliotheken?
Bibliotheken sind vielmehr als Orte um Bücher zu leihen. Als Kultur- und Weiterbildungsorte und Orte des Miteinanders sind Bibliotheken zentrale Ankerpunkte im Kiez. Um sich fit für die Zukunft zu machen, müssen auch Bibliotheken datenbasiert arbeiten. Wer fragt noch Sachbücher nach? Gibt es mehr Online-Ausleihen als am Schalter? Und welche Bevölkerungsgruppen werden mit dem Angebot eigentlich noch angesprochen? Bibliotheken können dabei auf detaillierte Nutzungs- und Bestandsdaten zurückgreifen. Die Stadtteilbibliothek Pankow hat sich als Pionierin auf den Weg gemacht, um diese Daten bestmöglich für ihre Arbeit zu nutzen.
Das Problem
Zu den regelmäßigen Aufgaben der Bibliothek gehört die Etatverteilung, Entscheidungen zur Bestandspflege (Makulatur), die Frage nach der Aktualität und Auslastung der Medien und der Vergleich zwischen den einzelnen Standorten. Weiterhin müssen jährlich Auswertungen erstellt werden, etwa für den Verbund Öffentlicher Bibliotheken Berlins (VÖBB). Im Kern geht es darum, wie die Bibliothek sich für die Zukunft aufstellen kann, um den Bedarfen aus der Bevölkerung gerecht zu werden.
Als Grundlage für diese Aufgaben können Daten über Ausleihen und Medienbestände genutzt werden. In der Praxis gestaltet sich diese Nutzung bisher allerdings nicht ganz einfach. Bisherige Auswertungen waren arbeitsintensiv, weil große CSV-Dateien manuell ausgewertet werden müssen und die Ergebnisse meist nicht visualisiert sind. Das führt dazu, dass Ergebnisse kaum vergleichbar und oft nur für einzelne Personen verfügbar sind. Es fehlt an unkomplizierten Datenpipelines zur Vorbereitung der Daten und an nutzendenfreundlichen Tools, die nicht nur für die technisch versierten Mitarbeitenden leicht zu bedienen sind.
Es fehlen vor allem:
- eine zentrale, einheitliche Ablage der Statistikdaten,
- eine einfache Möglichkeit, Zeitreihen zu vergleichen,
- eine leicht anpassbare, bedarfsgerechte Darstellung bzw. Visualisierung der Daten, die auch nicht-technische Mitarbeitende nutzen können.
Zielsetzung
Der Data Hub wird eingesetzt, um den Prozess zur Vorbereitung der Daten zu automatisieren und auf einem Dashboard für die Auswertung durch die Fachpersonen zur Verfügung zu stellen:
-
Datenbasierte Entscheidungen sollen Bibliotheken befähigen, ihren Bestand gezielter zu steuern und die Etatverteilung transparenter zu gestalten. Das Dashboard zeigt, wie sich Nutzung, Bestand und Zukäufe entwickeln, und schafft so eine Grundlage für fundierte Entscheidungen statt reiner Erfahrungswerte.
-
Weniger manueller Aufwand entlastet die Mitarbeitenden bei der jährlichen Auswertung. Durch die zentrale Verarbeitung im Data Hub werden Tabellen und Berichte automatisch generiert, was Zeit spart und die Vergleichbarkeit zwischen Bibliotheken verbessert.
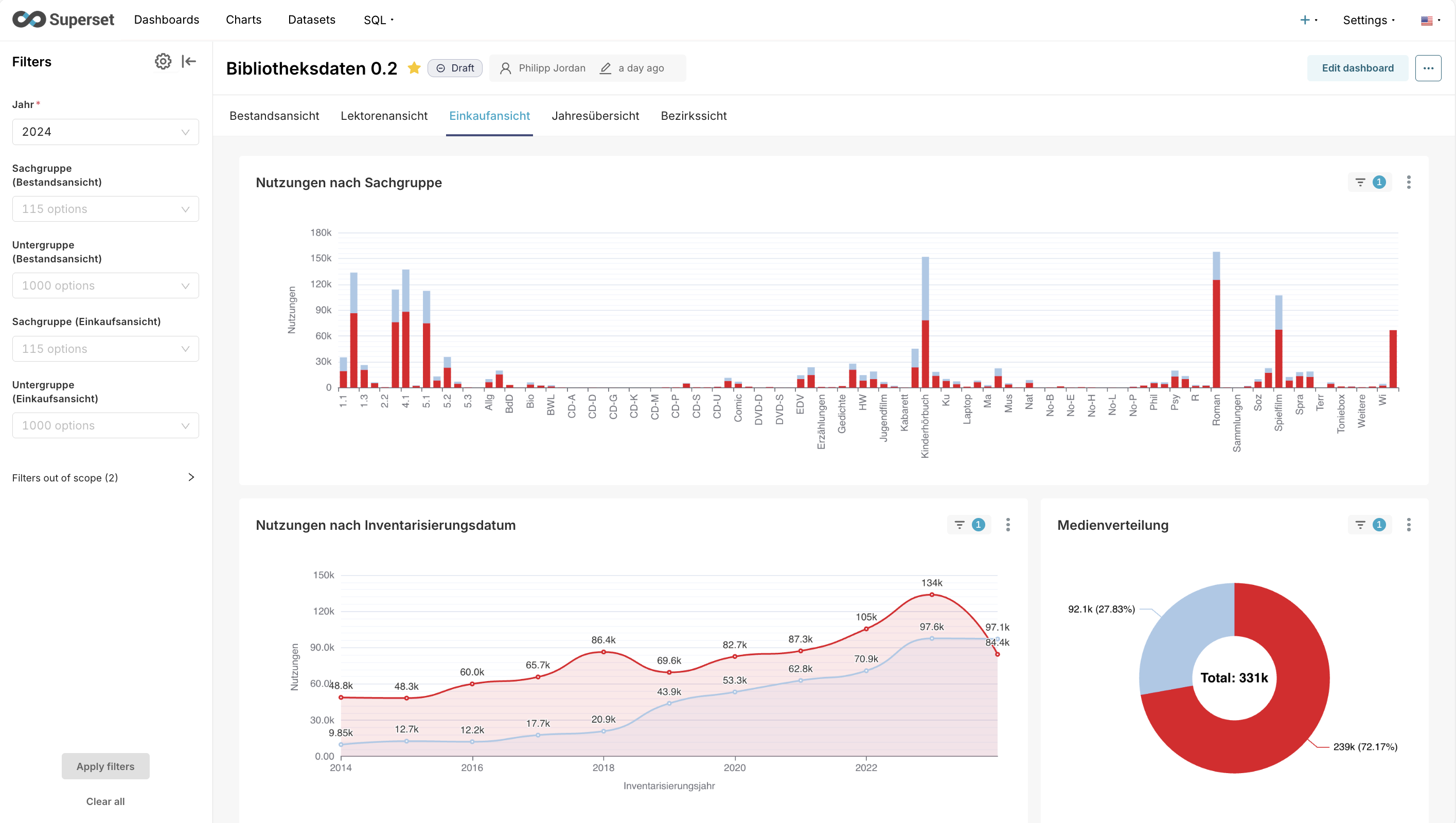
Impressionen eines ersten Prototypen des Dashboards
Die Umsetzung
Der Rahmen des Pilotprojekts
- Daten
- Zielgruppen
- Beteiligte
Die Daten
Grundlage des Projekts sind die jährlich erhobenen BesEx-Statistikdaten der Pankower Stadtbibliotheken. Sie enthalten Informationen zu Ausleihen, Beständen, Medienarten, Sachgruppen und Lieferanten in einer standardisierten CSV-Struktur.
Die Zielgruppen
Das Dashboard „Datenbasierte Bibliothek“ richtet sich an:
- Lektor:innen der Bibliotheken – zur Bewertung, Planung und Pflege des Bestands.
- Bibliotheksleitungen – zur strategischen Steuerung, Etatplanung und Berichterstattung (z. B. an den VÖBB).
- Interessierte Öffentlichkeit – perspektivisch über eine zusätzliche öffentliche Variante des Dashboards oder Veröffentlichungen.
Die Beteiligten
Am Pilotprojekt „Datenbasierte Bibliothek“ arbeiten diese Partner zusammen:
- Janusz-Korczak-Bibliothek Pankow – Initiatorin und Datenlieferantin des Projekts.
- Technologiestiftung Berlin – technische Umsetzung, Datenintegration und Dashboard-Entwicklung.
- Weitere Bibliotheken und VÖBB – perspektivisch sollen andere Bibliotheken auf das Projekt aufsetzen können.
Technische Umsetzung
Die Umsetzung im Data Hub Berlin basiert auf einer modularen Datenpipeline, von der Ablage über die Verarbeitung bis zur Analyse.
-
Speicherung:
Die Bibliothek liefert ihre jährlichen Statistikdaten im BesEx-Format. Diese Rohdaten werden im Data Hub harmonisiert und im Objektspeicher MinIO abgelegt. -
Verarbeitung und Analyse:
Über Node-RED werden die umfangreichen CSV-Dateien automatisch eingelesen, in kleinere Datensätze aufgeteilt und in die PostgreSQL-Datenbank importiert. In der Datenbank werden anschließend bibliothekstypische Kennzahlen berechnet, zum Beispiel:- Bestandsanteil (Anteil eines Exemplars am Gesamtbestand)
- Ausleihanteil (Anteil der Ausleihen dieses Exemplars an allen Ausleihen)
- Umsatz (Ausleihen im Verhältnis zum Bestand)
- Effizienz (Bestandsanteil im Verhältnis zum Ausleihanteil)
- Aktivierungsgrad (wurde ein Medium im Zeitraum überhaupt genutzt?)
Die Analysen orientieren sich an der Systematik für Bibliotheken (SfB), diese Struktur ermöglicht Vergleiche zwischen Themenbereichen, Häusern und Jahren.
-
Visualisierung:
Die bereinigten Daten fließen in Apache Superset, wo ein interaktives Dashboard entsteht. Darin können Bibliotheksleitungen und Lektorierende:- nach Zeiträumen filtern,
- einzelne Sachgruppen vergleichen,
- Zugang und Abgang einsehen,
- Ausleihen pro Lieferant oder Medienart betrachten
Organisatorische und methodische Begleitung
Ein nutzerzentrierter Ansatz prägte die Zusammenarbeit mit der Janusz-Korczak-Bibliothek. Das Dashboard wurde gemeinsam mit dem Ziel entwickelt, Anforderungen und Arbeitsabläufe der Bibliothek direkt in die Gestaltung einzubeziehen. Ein strukturierter Service Blueprint half, sowohl die Nutzungssituationen als auch die technischen Prozesse im Hintergrund sichtbar zu machen.
Workshops und Tests begleiteten den Entwicklungsprozess.
In drei Terminen wurden gemeinsam die zentralen Fragen und Kennzahlen definiert, die das Dashboard beantworten soll. Derzeit testen Lektorierende den Prototyp, um zu prüfen, ob er ihre praktischen Fragestellungen abbilden kann.
Wie geht’s weiter?
Zentrale Erkenntnisse
-
Datenarbeit braucht Zusammenarbeit.
Die gemeinsame Entwicklung mit der Janusz-Korczak-Bibliothek hat gezeigt, wie wichtig es ist, technische und fachliche Perspektiven früh zu verbinden. Nur durch diesen Austausch konnten Anforderungen präzise formuliert und praktikable Lösungen gefunden werden. -
Standardisierte Formate erleichtern die Integration.
Das BesEx-Format hat sich als gutes Beispiel erwiesen, Daten strukturiert in den Data Hub zu überführen. Auf dieser Grundlage lassen sich große Datenmengen automatisiert verarbeiten; ein wichtiger Schritt hin zu skalierbaren Dashboard-Lösungen. -
Visualisierung senkt Barrieren.
Ein klar gestaltetes Dashboard hilft, den Zugang zu Daten zu öffnen. Es zeichnet sich ab, dass viele Mitarbeitende, die bisher wenig mit Statistik gearbeitet haben, durch die Visualisierungen einen neuen Zugang zu ihren eigenen Fragestellungen gewinnen.
Nächste Schritte
Der Prototyp wird derzeit durch die Nutzenden vertestet. Das Feedback wird gesammelt und genutzt, um das Dashboard weiterzuentwickeln und zu optimieren.
Durch jährliche Datenupdates und automatisierte Prozesse im Data Hub bleibt die Lösung langfristig aktuell und leicht erweiterbar. Perspektivisch sollen weitere Berliner Bibliotheken eingebunden werden, da viele bereits mit dem gleichen BesEx-Datenstandard arbeiten. Dabei können die Vorarbeiten im Data Hub, wie die Datenverabreitung und Visualisierung leicht auf die anderen 11 Bezirke übertragen werden.